Compress Better, Compute Bigger

Have you ever experienced the frustration of not being able to analyze a dataset because it's too large to fit in memory? Or perhaps you've encountered the memory wall, where computation is hindered by slow memory access? These are common challenges in data science and high-performance computing. The developers of Blosc and Blosc2 have consistently focused on achieving compression and decompression speeds that approach or even exceed memory bandwidth limits.
Moreover, with the introduction of a new compute engine in Blosc2 3.0, the guiding principle has evolved to "Compress Better, Compute Bigger." This enhancement enables computations on datasets that are over 100 times larger than the available RAM, all while maintaining high performance. Continue reading to know how to operate with datasets of 8 TB in human timeframes, using your own hardware.
The Importance of Better Compression
Data compression typically requires a trade-off between speed and compression ratio. Blosc2 allows users to fine-tune this balance. They can select from a variety of codecs and filters to maximize compression, and even introduce custom ones via its plugin system. For optimal speed, it's crucial to understand and utilize modern CPU capabilities. Multicore processing, SIMD, and cache hierarchies can significantly boost compression performance. Blosc2 leverages these features to achieve speeds close to memory bandwidth limits, and sometimes even surpassing them, particularly with contemporary CPUs.
However, improved compression is only part of the solution. Rapid partial decompression is crucial when quick access to large datasets is needed. Blosc2 features n-dimensional containers that support flexible slicing, essential for non-linear data access. Leveraging two-level partitioning, Blosc2 delivers high-speed data access. Think of Blosc2 as a compressed-data version of "NumPy". Furthermore, data can reside in memory, on disk, or across a network.
A significant challenge is leveraging compression to overcome the memory wall, which hinders computation in many scenarios. The memory wall arises when the CPU waits for data from memory, a slow process relative to CPU speed. Addressing this requires tightly integrating compression and computation, utilizing all available hardware resources.
Computing with Blosc2
The integrated compute engine in Blosc2 3.x enables the calculation of complex expressions on datasets much larger than available memory. By leveraging CPU caches, Blosc2 temporarily stores there decompressed data chunks from compressed containers, allowing the CPU to operate on cached data, minimizing memory access.
To illustrate this, we'll use a reduction calculation as a simple example. Reductions are frequently used in data science to create informative summaries of large datasets. Here, we will reduce the result of a complex expression that involves large, n-dimensional datasets.
Here it is the core Python code that we will use:
import numpy as np
import blosc2
N = 1000_000 # this will vary
dtype = np.float64
a = blosc2.linspace(0, 1, N * N, dtype=dtype, shape=(N, N))
b = blosc2.linspace(1, 2, N * N, dtype=dtype, shape=(N, N))
c = blosc2.linspace(0, 1, N, dtype=dtype, shape=(N,)) # 1D array; broadcasting is supported
out = np.sum(((a ** 3 + np.sin(a * 2)) < c) & (b > 0), axis=1)
The blosc2.linspace function generates a dataset of a specified shape, populated with a linearly spaced sequence. We utilize it to initialize the a, b, and c operands. Subsequently, we compute the reduction of the expression ((a ** 3 + np.sin(a * 2)) < c) & (b > 0) along the first axis, assigning the result to the out variable. This expression leverages NumPy functions on Blosc2 arrays because Blosc2 NDArrays override NumPy's universal functions (ufuncs), substituting them with optimized Blosc2 counterparts for enhanced performance. Additionally, standard NumPy broadcasting is supported, enabling the comparison of a 1D array c with a 2D array a.
The experiments were conducted on a machine equipped with an AMD Ryzen 9 9800X3D processor, running Ubuntu Linux 24.10 and featuring 64 GB of RAM, along with a high-speed SSD (up to 7 GB/s for sequential reads). The software stack included Python 3.13.1, Python-Blosc2 3.2.0, Numexpr 2.10.2, NumPy 2.2.3, Zarr 3.0.4, Dask 2025.2.0 and Numba 0.61.0.
Compression vs. No Compression
To begin, let's evaluate Blosc2's performance with and without compression. We measured the computation time for the reduction across varying working set sizes. The results are visualized in the following plot:
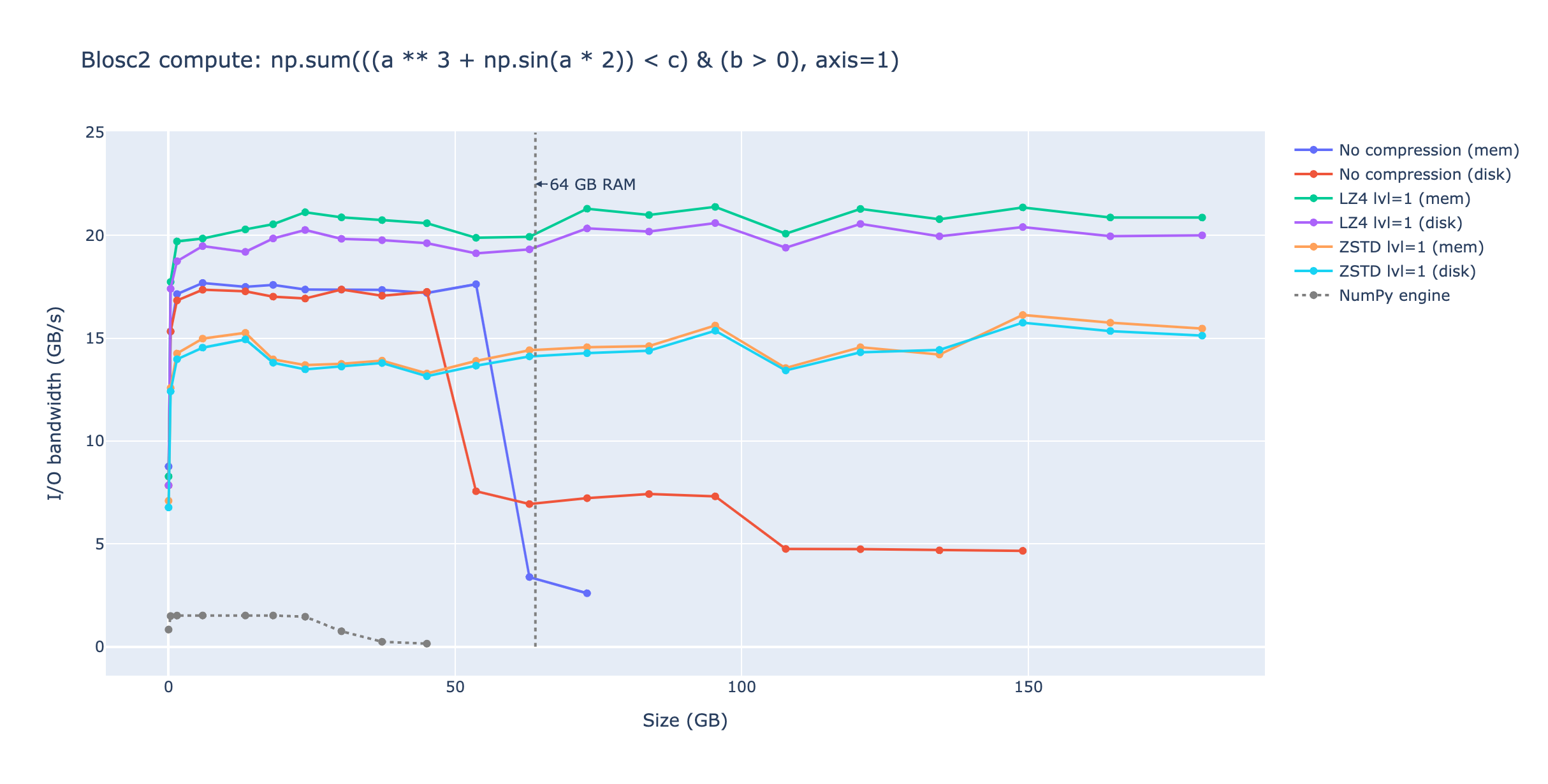
Blosc2 significantly outperforms NumPy in this case for both in-memory and on-disk datasets, achieving speeds more than 10x faster. This is primarily because: 1) Blosc2 utilizes Numexpr internally when feasible, reverting to NumPy only when Numexpr cannot handle the operation (such as the reduction step), and 2) Blosc2 stores intermediate results in CPU caches, minimizing memory access. Furthermore, using fast compression (LZ4+shuffle) yields the best performance (surpassing even uncompressed scenarios) as the time to fetch and decompress data is less than fetching uncompressed data directly from memory.
It's also noteworthy that Blosc2 maintains its performance for significantly larger working set sizes compared to NumPy. The plot illustrates that Blosc2 can compute the expression for working sets up to 180 GB without a performance decrease when compression is enabled. Without compression, Blosc2 scales effectively up to 55 GB before experiencing performance degradation. In contrast, NumPy's performance starts to decline at 30 GB. This disparity arises because NumPy utilizes temporary arrays to store intermediate results, whereas Blosc2 employs smaller temporaries that fit within CPU caches, thereby minimizing memory accesses.
Blosc2 vs. Other Solutions
We compared Blosc2 with other data containers and compute engines, including Zarr (a data container that can use Blosc compression), Dask (a parallel computing library for NumPy), and Numba (a just-in-time compiler for NumPy expressions). Numba, which requires NumPy containers and lacks native compression or on-disk data support, was included for reference. This evaluation focuses on in-memory datasets, and the results are presented below.
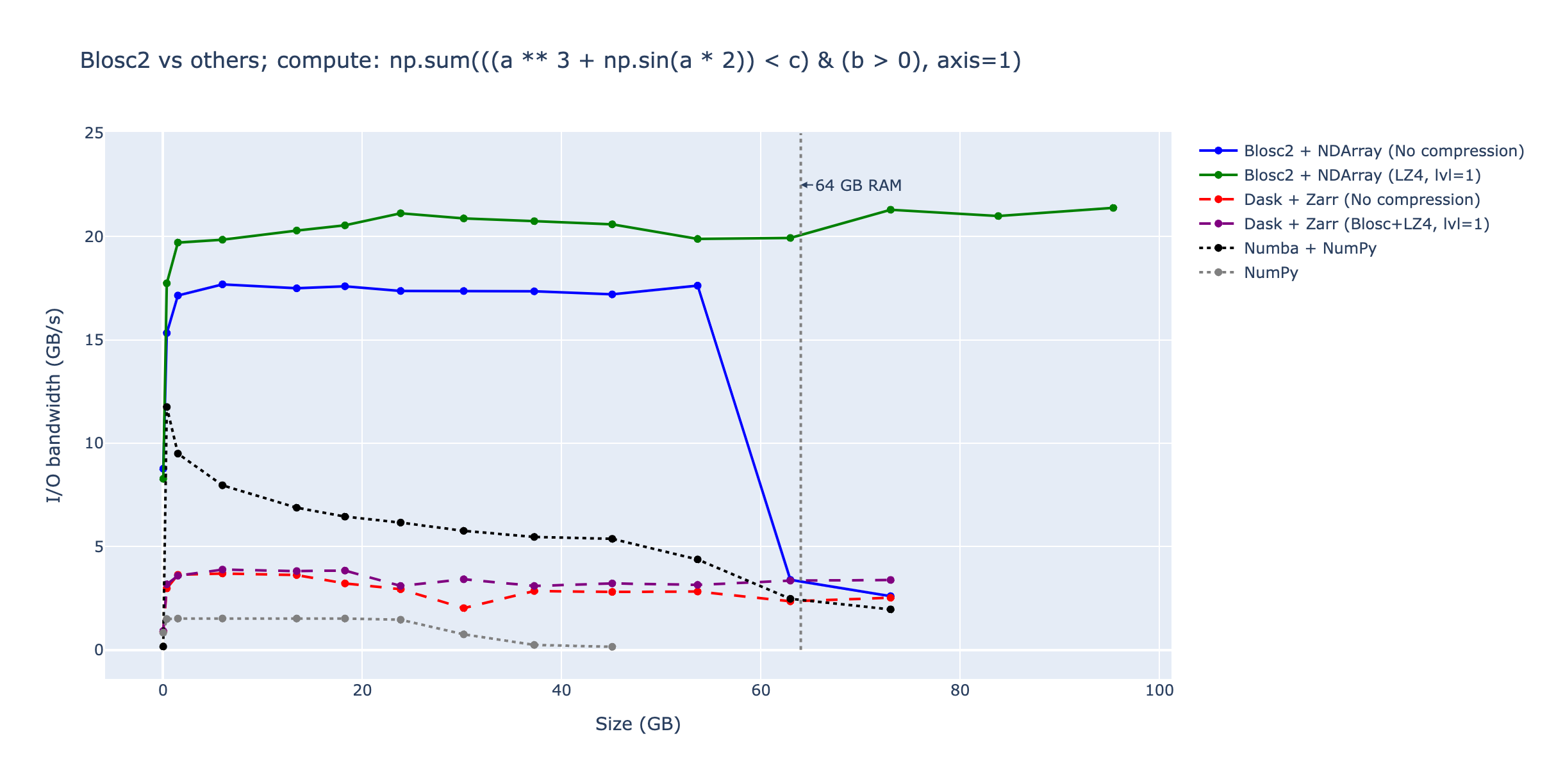
In this scenario, Zarr's compression (via Blosc+LZ4) enhances Dask's performance, maintaining it even when the working set size exceeds available RAM due to Dask's blocked computation algorithms. However, Blosc2 computes the expression significantly faster than Zarr+Dask, both with and without compression (LZ4 in this case). This advantage stems from Blosc2's tight integration of compression and computation, which minimizes buffer copies and memory accesses. It's worth noting that uncompressed Blosc2's performance decreases to Zarr+Dask levels when the working set size surpasses available RAM, while compressed Blosc2 continues to perform well with larger working set sizes.
On the other hand, Numba computes the expression faster than NumPy and Zarr+Dask but doesn't scale well for larger working set sizes. Its performance significantly decreases below Zarr+Dask levels when exceeding available RAM. The reason for Numba's poor scaling with larger working set sizes is unclear, although it may require rewriting the expression with explicit loops for optimal performance, which falls outside the scope of this experiment.
Compute Bigger (Beyond RAM)
A valid question is whether Blosc2's scalability with compression can continue indefinitely. The answer is no; RAM has a finite capacity. Once the compressed working set size exceeds the available RAM, performance will inevitably decrease. To investigate this, we conducted the same experiment, but with extended working set sizes up to 8 TB. The results are shown below:
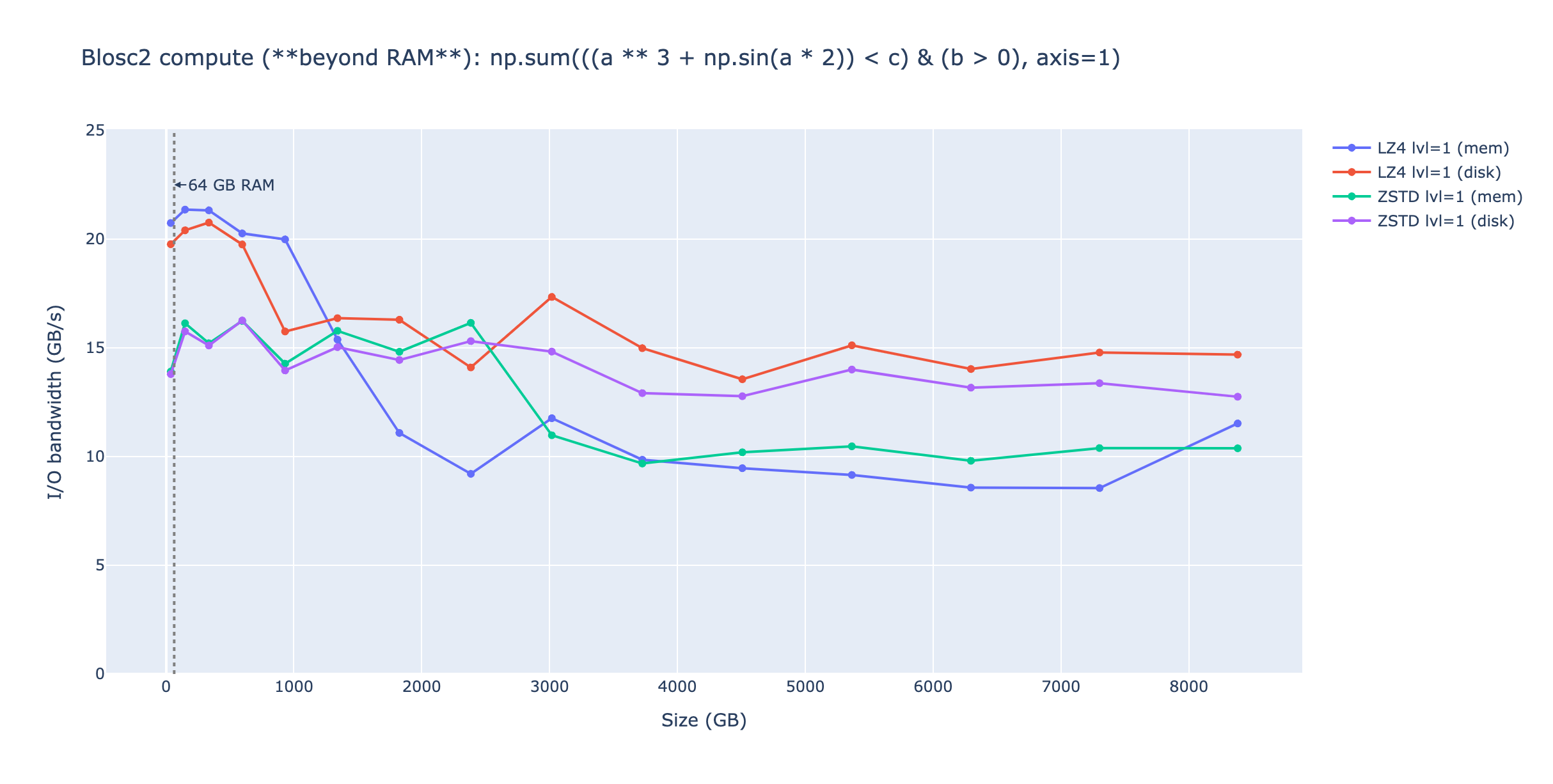
We focused our extended size range tests on LZ4 and ZSTD codecs due to the substantial working sizes involved, which would have resulted in prohibitively long run times for non-compression scenarios. With LZ4, Blosc2 maintains high-performance reduction computations for in-memory datasets up to 1 TB and on-disk datasets up to 600 GB. Beyond these thresholds, performance decreases moderately; however, on-disk datasets exhibit superior scaling compared to in-memory datasets, achieving faster speeds for working set sizes exceeding 1 TB.
With ZSTD, performance degradation occurs later (around 2.5 TB) due to its superior compression ratios compared to LZ4 (approximately 2.5x better in this scenario). Beyond 3 TB, on-disk performance surpasses in-memory performance, mirroring the behavior observed with LZ4 but at larger working set sizes.
So, in general, but also in terms of performance, on-disk datasets are preferable for very large working set sizes due to their superior scaling compared to in-memory datasets. Even for medium-sized datasets, the performance of on-disk storage closely matches that of in-memory. Additionally, storing datasets on disk offers the convenience of persistent storage and reusability.
Reproducing the Experiments: The code used in these experiments is available in the Blosc2 repository. To replicate the results, ensure you have Blosc2, Numexpr, NumPy, Zarr, Dask, and Numba installed. A machine with at least 32 GB of RAM (64 GB recommended), a 1.5 TB swap area, and 600 GB of free disk space is also required. For optimal performance, a CPU with a large cache (32 MB or more) is recommended.
Conclusion
In summary, Blosc2 achieves superior compression and enables computation on larger datasets by tightly integrating compression and computation, interleaving I/O and computation, and utilizing great libraries like Numexpr and NumPy. This allows Blosc2 to handle significantly larger working sets than other solutions, delivering high performance for both in-memory and on-disk datasets, even exceeding available RAM (up to 8 TB in our tests, but you can go as far as your disk allows).
IronArray proudly supports Blosc2's development, recognizing its pivotal role in our data processing tools. We eagerly anticipate upcoming features and the continued evolution of Blosc2.
Appendix (2025-04-28)
The array interface protocol has been implemented for all Blosc2 array containers in Python-Blosc2 3.2.1. This enhancement allows direct use of most NumPy functions with native Blosc2 containers, creating a familiar experience for NumPy users. This integration enables you to benefit from Blosc2's powerful compression and decompression capabilities, while still leveraging NumPy's comprehensive function library. On the other hand, this allows Blosc2 containers to be seamlessly used with Pandas, Numba, Dask, CuPy and others.
For a practical demonstration, examine the performance comparison between Blosc2, NumPy, and Numba when performing in-memory computation with the NumPy cumsum() function. This function hasn't yet been specifically optimized in either Blosc2 or Numba, but as the c array is relatively small, this should not hinder performance too much. The benchmark uses a 32 GB working set (uncompressed), which fits within the available 64 GB RAM of our test system:
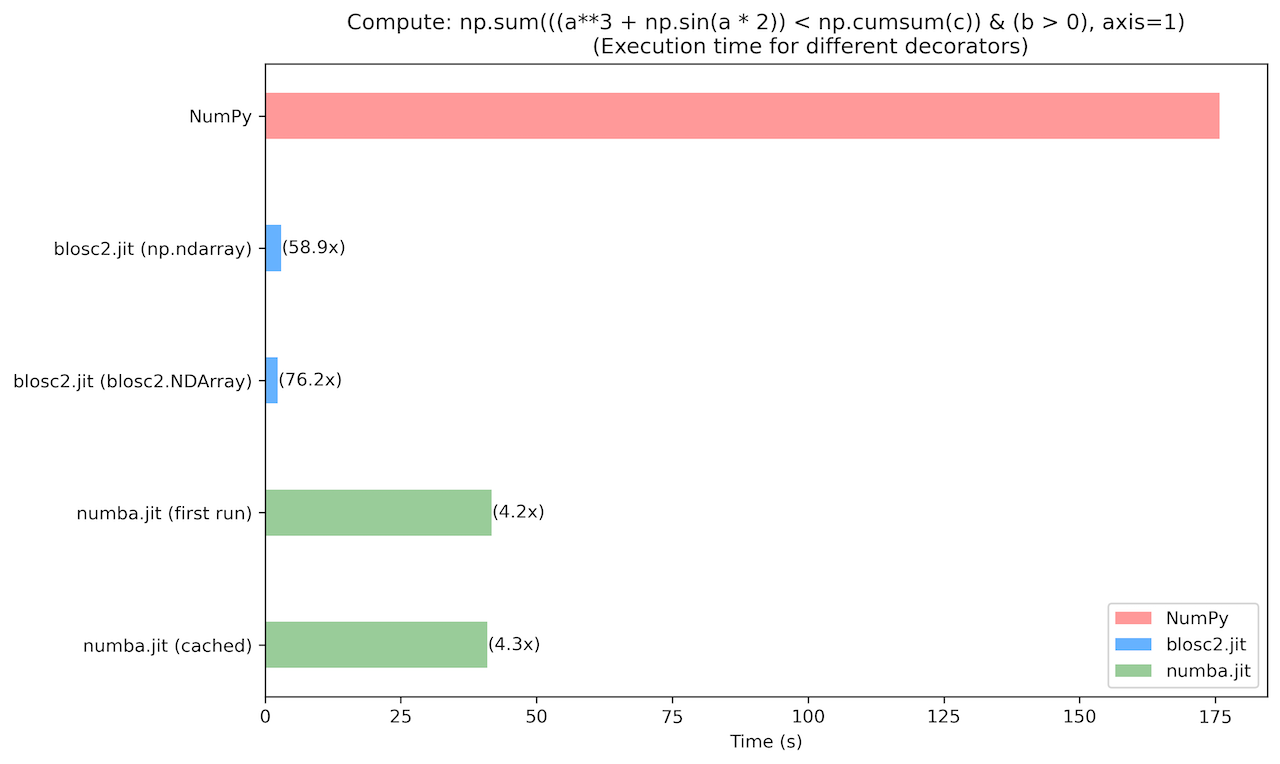
For reproducibility, see benchmark sources.