Bringing Blosc2 to Heel

There are many array libraries in the scientific and data ecosystem that provide native array types (Numpy, PyTorch, Zarr, h5py, PyTables, JAX, Blosc2) and an even larger list of those that ''consume'' these provided array types (Scikit-Learn, Parcels, Dask, Pillow, ScikitImage). Moroever, the division between the two groups is not very cleancut - PyTorch tensors are wrappers for NumPy arrays, and thus straddle the boundary between array provider and consumer.
Such a high degree of interdependency makes it crucial that array objects are portable between libraries - this means that the array objects must be standardised between libraries, but also that the libraries are equipped with a minimal set of functions that have the same names and signatures across the ecosystem, and that know how to ingest, produce and process the arrays. The ideal would be to be able to write code that works with arrays
import array_lib as xp
#
# Do array things with library
#
and then simply swap in any array library array_lib and have the code run.
From this set of concerns has sprung an open-source effort to develop the array API standard, along with an extensive associated test suite, to drive the array ecosystem towards this holy grail of interoperability.
Blosc2 and the array API
Blosc2 has been developed with the array API in mind from an early stage, but it is only now that ironArray has been able to dedicate development time to integration efforts. While the standard and test suite are still evolving (the latest version was released in December 2024), it is sufficiently stable to form the basis for ironArray's work.
Over the last month we have made some big steps forward, so that the flagship NDArray object has all the methods and attributes required by the standard, as well as implementing key functions, indexing routines and global variables in an efficient way, meshing with Blosc2's compression-first, chunked approach. In the latest Blosc2 version 3.9, among the approximately 70 new functions, methods and attributes, we have extended matrix multiplication and offer an efficient tensordot routine. As a taster of the linear algebraic power that these improvements have brought to Blosc2, we'll do some benchmarking of this below.
ironArray's dedication to the project has also enabled the contribution of around 10 new functions to the numexpr open source library, on which much of Blosc2's computation backend relies, and which enables Blosc2 to perform memory-efficient computations that are nonetheless often faster than NumPy. For example, the highly optimised hypot function in numexpr (which can make use of Intel MKL routines) requires 10% of the NumPy computation time when used directly on NumPy arrays:
import timeit
import numpy as np
import numexpr as ne
# --- Experiment Setup ---
n_frames = 50000 # Raise this for more frames
dtype = np.float64 # Data type for the grid
# --- Coordinate creation ---
x = np.linspace(0, n_frames, n_frames, dtype=dtype)
y = np.linspace(-4 * np.pi, 4 * np.pi, n_frames, dtype=dtype)
X = np.expand_dims(x, (1, 2)) # Shape: (N, 1, 1)
Y = np.expand_dims(x, (0, 2)) # Shape: (1, N, 1)
>>> Average time for np.hypot(X, Y): 1.34 s
>>> Average time for ne.evaluate('hypot(X, Y)'): 0.145 s
All in all, Blosc2 has acquired some impressive functionality, with new, optimised functions for:
- linear algebra (
tensordot,diagonal,vecdotandouter) - elementwise
maximimum/minimum //(floor division)- bitwise and logical AND/OR/XOR/NOT and bitwise left/right shift
log2hypotcliproundandtruncmeshgridnextafter,copysign,signandsignbit
In addition, we have increased the maximum number of supported array dimensions from 8 to 16!
Tensordot in Blosc2
The tensordot function in the array API standard implements a generalisation of matrix multiplication. Matrix multiplication can be understood as a multiplication-and-sum reduction of the elements along the columns of an M x N matrix and the rows of an N x P matrix, giving an M x P matrix as a result. In a similar way, we may introduce a generalised operation which multiplies and sums elements to reduce along an arbitrary number of axes of two N-D arrays, defined if the axes are of the same length. Thus for an array A of shape (A1, A2, ..., An) and an array B of shape (B1, B2, ..., Bm), if reduced along axes (2, 3) and (1, 4), the tensordot is defined if A2=B1 and A3=B4, and the result will have shape (A1, A4, ..., An, B2, B3, B5, ..., Bm) (i.e the non-contracted axes of A followed by the non-contracted axes of B).
We consider the tensordot of N x N x N arrays over three different sets of axes ((0, 1), (1, 2), (2, 0)), and compare the performance of Blosc2 and NumPy implementations. See the plot below, where the coloured bars indicate the average computation time over the three axes cases and the error bars the maximum and minimum time.
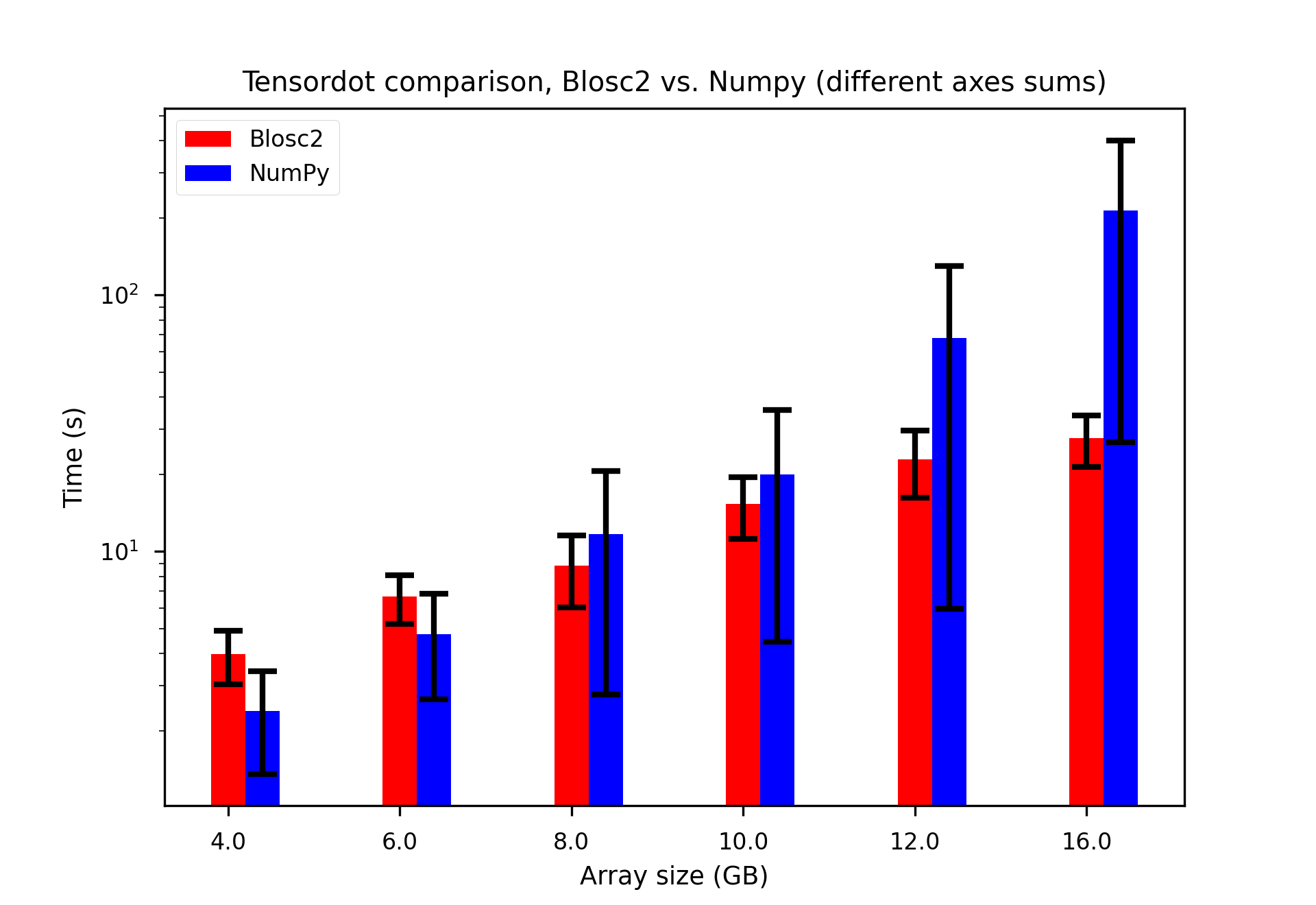
Clearly once the array sizes approach an appreciable fraction of the total RAM, NumPy suffers significant slowdowns - being up to 12x slower than Blosc2 in the worst case - which Blosc2 is able to avoid. We have selected an isomorphic chunk shape for the Blosc2 arrays, to equalise performance between the different reduction axes - of course this could be optimised to favour specific axes (see this tutorial for a deep dive into reductions and chunking).
The experiments were conducted on a machine equipped with an Intel 13900K processor, running Ubuntu Linux 25.04 and featuring 32 GB of RAM. The software stack included Python 3.12.11, Python-Blosc2 3.9.1, Numexpr 2.13.0 and NumPy 2.0.0. The benchmark code can be found here.
Roadmap to full compliance
Given that even NumPy is not 100% compliant with the array API standard, it is clear how much effort must be invested by array libraries to move over to the standard. There are several essential functions such as diff, reshape, tile, repeat and unique_counts that are hard due to Blosc2's chunked-and-compressed approach (although one can expect performance benefits due to improved memory efficiency once implemented). Some existing routines can also be made more efficient via introducing fast paths for special, but common, cases.
In addition, although Blosc2 does not bring GPU support, it is necessary to provide an interface to DLPack, which has proven quite difficult in the NumPy case (which is also a CPU-only library).
ironArray has the talent and energy to bring Blosc2 into line, but it is not always possible to dedicate development time to the project. If you appreciate what we're doing with Blosc2, please think about supporting us. Your help lets us keep making these tools better.
Conclusion
Blosc2 achieves superior compression and enables computation on larger datasets by tightly integrating compression and computation, interleaving I/O and computation, and utilizing mature, powerful libraries like Numexpr and NumPy. This allows Blosc2 to handle significantly larger working sets than other solutions, delivering high performance for both in-memory and on-disk datasets, even exceeding available RAM.
By bringing Blosc2 into greater alignment with the interlibrary array API standard, we can bring these benefits to a wider range of users and applications. The benefits observed even for freshly-implemented complex linear algebra operations like tensordot underlines the strength of Blosc2's compression-first, memory-optimised philosophy. Likewise, tightly integrating data storage and computation via powerful chunkwise operations and the numexpr backend marries the speedups of compiled C++ code with the memory efficiency of chunking.
IronArray proudly supports Blosc2's development, recognizing its pivotal role in our data processing tools. We eagerly anticipate upcoming features and the continued evolution of Blosc2 into a mature, fully array API-compliant library.