Matrices, Blosc2 and PyTorch


One of the core functions of any numerical computing library is linear algebra, which is ubiquitous in scientific and industrial applications. Much image processing can be reduced to matrix-matrix or matrix-vector operations; and it is well-known that the majority of the computational effort expended in evaluating neural networks is due to batched matrix multiplications.
At the same time, the data which provide the operands for these transformations must be appropriately handled by the library in question - being able to rapidly perform the floating-point operations (FLOPs) internal to the matrix multiplication is of little use if the data cannot be fed to the compute engine (and then whisked away after computation) with sufficient speed and without overburdening memory.
In this space, PyTorch has proven to be one of the most popular libraries, backed by high-performance compiled C++ code, optional GPU acceleration, and an extensive library with a huge array of efficient functions for matrix multiplication, creation and management. It is also one of the most array API-compliant libraries out there.
Blosc2 and Linear Algebra
However PyTorch does not offer an interface for on-disk data. This means that when working with large datasets which do not fit in memory, all data must be fetched in batches into memory, computed with, and then saved back to disk, using another library such as h5py. This secondary library also handles compression so as to reduce storage space (and increase the I/O speed with which data is sent to disk).
Blosc2 is an integrated solution which provides highly efficient storage via compression and marries it to a powerful compute engine. One can easily write and read compressed data to disk with a succint syntax, with decompression and computation handled efficiently by the computational workhorse. In addition, the library automatically selects optimal chunking parameters for the data, without any of the ad-hoc experimentation required to find 'good' batch sizes.
This chunking is naturally important for the compression engine, but the compute engine benefits even more, with the chunks optimised for the cache hierarchy so that memory can be maximally utilised and computation accelerated - even for fully in-memory calculation, Blosc2 can perform complex linear algebra and other computations 5-10x faster than NumPy.
Comparing Blosc2 and PyTorch
Let's look at a simple example of an image transformation. We will use a dataset based on a real 3D tomography obtained from an X-ray diffraction experiment. The dataset consists of 2000 images of shape (2167, 2070).
The full pipeline of: 1) loading data from disk, 2) (batched-/chunked-)computation in memory and 3) saving of results to disk is thus of clear relevance to science and industry. As a benchmark for how our numerical libraries compare for this use case, we will process a large on-disk dataset of 2000 images of shape (2167, 2070) via multiplying each image by one of 2000 matrices of size (2000, 2167). We will then save the results back to disk. We can imagine that the instrument used to record the images has some drift which changes over time and which corrupts the images, and which we may correct via the matrix transformation - here we 'recover' a ripple that is not in the original image.

Once the dataset and the matrices have been saved to disk (in either the .b2nd or .h5 format for Blosc2 and h5py/PyTorch respectively) we may proceed to the calculation. For the dataset, transformation matrices, and result we use the same compression parameters ('lz4' compressor, SHUFFLE filter and compression level 1) and allow Blosc2/h5py to select chunk shapes automatically. The matrices are stored in single-precision (float32), and so the size of the operands and result is 96.6GB in total.
This calculation is remarkably concise in the case of Blosc2:
A = blosc2.open("transform.b2nd", mode="r")
B = blosc2.open("kevlar.b2nd", mode="r")
# Perform matmul A@B and write to out file
out_blosc = blosc2.matmul(A, B, urlpath='out.b2nd', mode="w", cparams=cparams)
For PyTorch we must handle the batching manually to avoid saturating memory and interface with h5py like so:
with h5py.File("my_kevlar.h5", "r+") as f:
A = f["transform"]
B = f["data"]
f.create_dataset("out", shape=out_blosc.shape, dtype=out_blosc.dtype, **h5compressor)
dset_out = f["out"]
# Perform matmul A@B and write to out file in batches
for i in range(0, len(A), batch_size):
batch_a = torch.from_numpy(dset_a[i:i+batch_size]).to(device)
batch_b = torch.from_numpy(dset_b[i:i+batch_size]).to(device)
result = torch.matmul(batch_a, batch_b)
dset_out[i:i+batch_size] = result.cpu().numpy()
Blosc2 is able to complete this workflow substantially quicker than PyTorch:
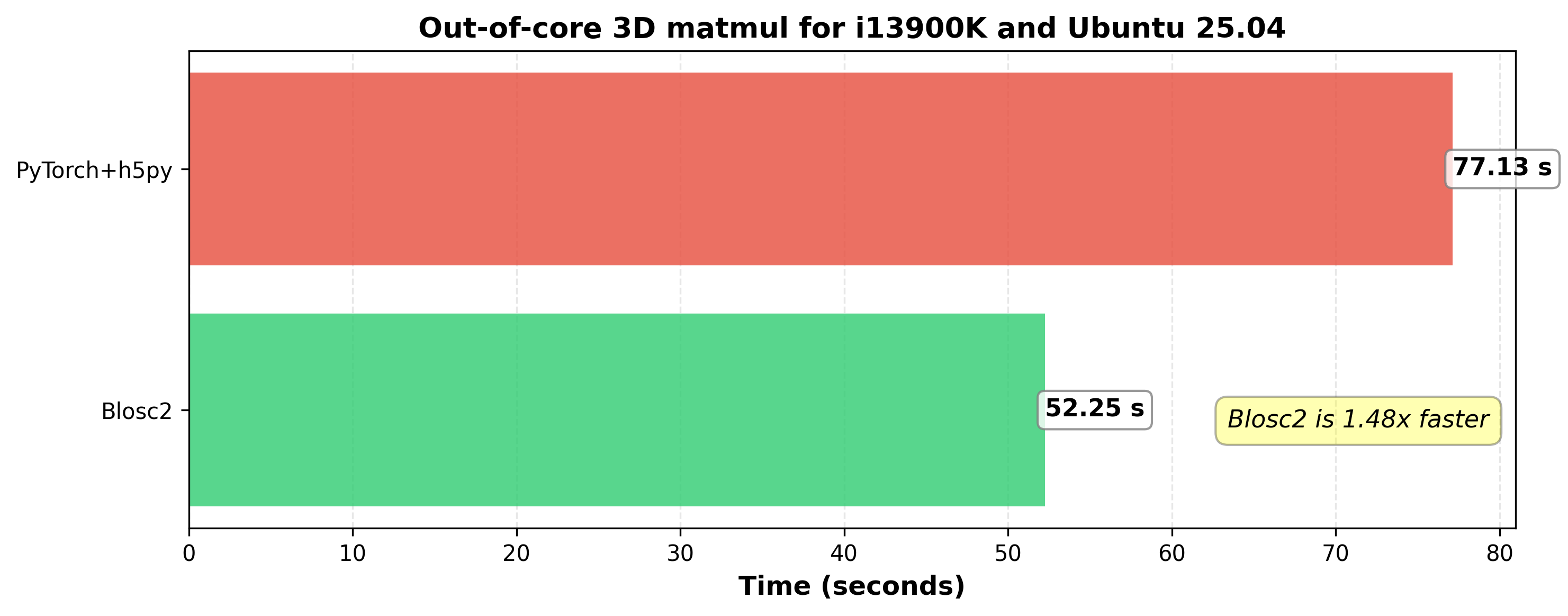
The experiments were conducted on a machine equipped with an Intel 13900K processor, running Ubuntu Linux 25.04 and featuring 32 GB of RAM, with an SSD hard drive. The software stack included Python 3.12.11, PyTorch 2.8.0, Python-Blosc2 3.11.0, and NumPy 2.3.3 with Intel MKL enabled. The benchmark code can be found here.
Benchmarking on ARM's Scalable Matrix Extension (SME)
We also tested performance on cutting-edge hardware featuring ARM's Scalable Matrix Extension (SME). SME accelerates matrix operations, and Apple's M4 CPU is one of the first to incorporate it. This makes it a compelling platform for comparing linear algebra performance.
The benchmark was executed on a Mac Mini with an M4 Pro CPU and 24 GB of RAM, meaning the 96.6 GB working set still far exceeded the available memory.
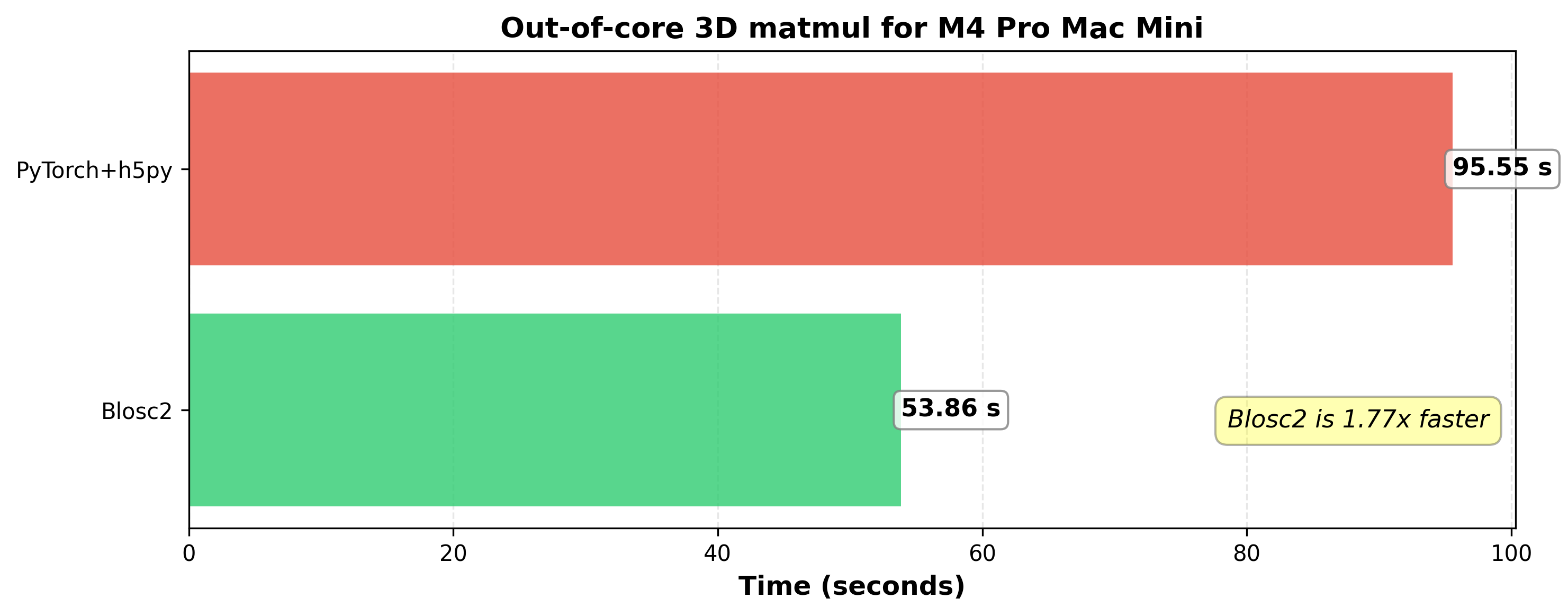
On this hardware, Blosc2's lead widens, performing significantly faster than PyTorch. Remarkably, the M4 Pro's performance of Blosc2 is on par with the Intel 13900K while consuming significantly less power. As compilers and libraries better leverage SME, we can expect even greater performance gains on this new generation of processors.
Conclusion
Blosc2 marries efficient compression to powerful computation, automating your large dataset workflows without you having to lift a finger or wait too long. Blosc2 delivers high performance for both in-memory and on-disk datasets, even exceeding available RAM, and is competitive with the state-of-the art in linear algebra.
Of course, PyTorch easily interfaces with GPU devices to accelerate computations (which we have not explored here), whereas Blosc2 does not provide GPU support. Part of the path to GPU support would be to provide an interface to DLPack (as required for array API compliance) - but this requires a significant investment of development time.
If you appreciate what we're doing with Blosc2 here at ironArray, please think about supporting us via contacting ironArray for consulting services. You can also sponsor the Blosc project in different ways. Your help lets us keep making these tools better.
ironArray proudly supports Blosc2's development, recognizing its pivotal role in our data processing tools. We eagerly anticipate upcoming features and the continued evolution of Blosc2 into a mature, fully array API-compliant library.